Die TUP-Reihe Analytics – Was ist ‚Descriptive Analytics‘
Big Data ist ein Begriff der uns als Software-Manufaktur schon eine geraume Zeit begleitet. Damit sind wir nicht alleine, wie ein kurzer Blick auf Google Trends zeigt. Doch ein Datenhaufen allein schafft noch keinen Mehrwert, dazu braucht es die effiziente Analyse dieser Daten. In der Beitragsreihe ‚Analytics‘ stellen wir daher diese Analysemethoden und ihren Mehrwert vor.
Die Herausforderung ‚Big Data‘ ist nicht erst seit 2011 mit ‚Industrie 4.0‘ ein zentrales Thema der stets optimierungsgetriebenen Intralogistik. Daten allerdings, die durch immer genauere und zahlreichere Sensoren aufgenommen werden, sind nur der erste Schritt, um aus diesen Informationen operativen Mehrwert zu schaffen. Der zweite Schritt ist Kontext. Als Software-Manufaktur sehen wir darin unsere Kernaufgabe, die wir mit unserem Leitsatz ‚Software follows function‘ abbilden.
Deskriptive Analyse in der Intralogistik
Die Grundlage für alle Analyseprozesse ist die deskriptive Analyse. Ihr Ziel ist es empirische Daten übersichtlich darzustellen und zuzuordnen. So lassen sich vergangene und derzeitige Zustände beschreibend darstellen. Ergänzend dazu müssen relevante Kennzahlen definiert werden, um die Lesbarkeit für Entscheider zu gewährleisten.
Die zentralen Kennzahlen der Intralogistik
Die gemessenen Hauptmetriken in den meisten Logistikzentren sind Zahlen zu Picks, Aufträgen, Transporten, Erfassungen, dem Bestand sowie das Zählen von Packstücken oder Ladeeinheiten.
Auf diese Metriken werden im nächsten Schritt Dimensionen angewendet. Dimensionen bezeichnen Merkmale dieser Daten. Die einfachste Dimension ist die Zeit, um beispielsweise die Anzahl der Picks oder Transporte pro Stunde oder Tag analysieren zu können. Komplexere Dimensionen sind Lagerzonen oder Mandanten.
Der Schlüssel zu einem möglichst hohen Mehrwert der deskriptiven Analyse in der Intralogistik ist es, die Kombination aus Dimensionen und Metriken zu finden, die den bestmöglichen Einblick in die Effizienz der Geschäftsprozesse liefert.
Saubere Daten als Grundlage für Smart Data
Der Unterschied zwischen Big Data, also einer großen Menge an Daten, aus der sich entweder keine oder nur bedingt Schlüsse ziehen lassen und Smart Data ist der individuell angepasste Kontext. Um Geschäftsprozesse zuverlässig zu analysieren und zu optimieren, helfen nur bestmöglich strukturierte Daten weiter. Eine weitere Anforderung ist, dass weitere Messwerte oder zu messende Objekte einfach in das Modell integriert werden können.
Objekte, Werte, Dimensionen und Ereignisse als Modellgrundlage
Die Grundlage für deskriptive Analyse ist ein möglichst flexibles und gleichzeitig strukturell verständliches Datenmodell, damit die aufbereiteten Daten auch tatsächlich wertbringend analysiert und interpretiert werden können.
Ein Objekt ist in der Intralogistik ein Vorgang oder ein physisches Objekt. Es kann also ein Pick sein, aber auch ein Ein- und Auslagervorgang eines Regalbediengeräts. Dabei entstehen Werte, die dem Objekt zugewiesen werden, wie sein Gewicht, seine Abmessungen oder seine aktuelle Position. Wichtig dabei ist, dass diese Werte quantifizierbar und allgemeingültig sein müssen.
Die Kombination aus Werten und Objekt macht transparent, was etwas ist und in welchem Zustand es sich befindet.
Ereignisse sind Instanzen, in denen zu dem Objekt Daten erhoben oder hinzugefügt werden. Wenn das Objekt sich beispielsweise auf einem Förderband bewegt, wird seine Position beim Passieren von Sensoren automatisch aktualisiert. Während dieses Vorgangs können dem Objekt auch Dimensionen zugeordnet werden.
Dimensionen sind Attribute von Werten, die diesen eine kontextbasierte Qualität geben. Um hier erneut auf das Beispiel des Objekts auf der Fördertechnik zurückzukommen: Über Messwerte und Ereignisse ist klar, wo es ist, was seine Abmessungen sind und was es ist. Über Dimensionen wird das „Warum?“ und „Wo?“ und „Wann?“ erweitert, in dem wir beispielsweise eine Auftragsnummer, das Lager oder die Lagerzone sowie die aktuelle Schicht im Lager als Dimension hinzufügen.
Der Vorteil dieses Modells ist, dass ein neuer Kontext einfach über Dimensionen abbildbar ist und dass es in den verschiedensten Situationen angewendet werden kann, solange die Daten gleichmäßig erhoben werden. Ob automatisierte Fördertechnik oder manuelle Kommissionierung macht in der Verwertbarkeit der Daten keinen Unterschied.
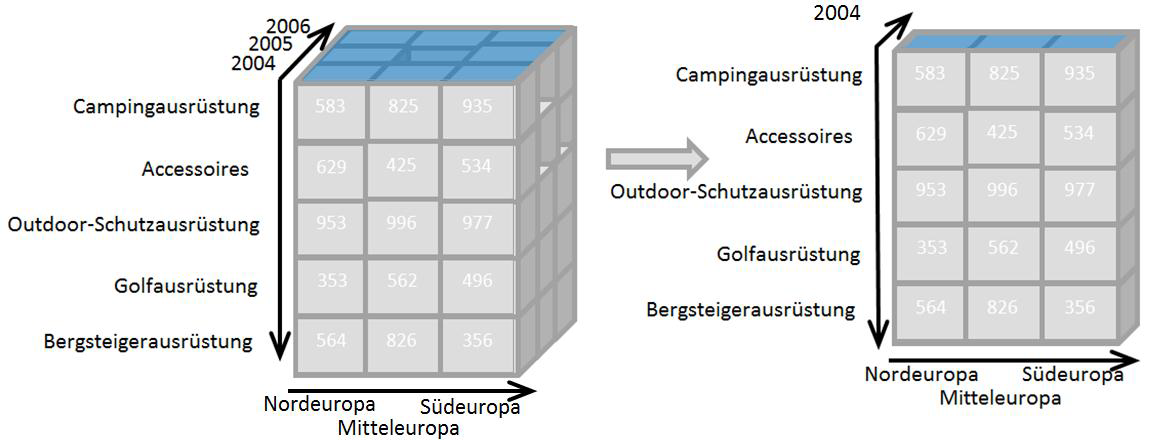
OLAP-Würfel als konfigurierbare Kontextspeicher
Daten, die mit Ereignissen, Werten und Dimensionen, um einen Kontext erweitert wurden, werden häufig in die Darstellungsform eines sogenannten OLAP- oder Datenwürfels gebracht.
{kind=link}
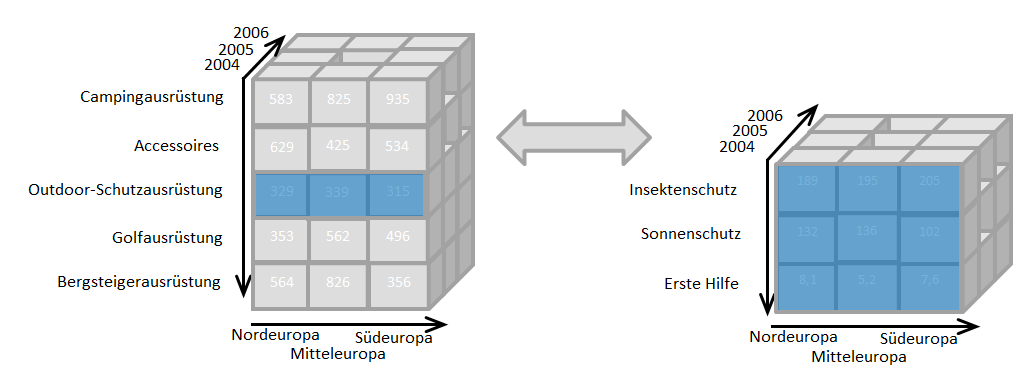
Entlang der Achsen dieses Würfels befinden sich die Dimensionen, die über verschiedene Filter in ihrer Komplexität reduziert oder auf konkrete Anwendungssituationen angepasst werden können. Die Besonderheit dieses Modells ist, dass es kleinere Varianten von sich beinhalten kann. Auf diese detaillierten Würfel kann dann über einen sogenannten Drill-Down zugegriffen werden.
{kind=link}
Die richtigen Filter finden
Das Ziel der deskriptiven Analyse ist relevante Kombinationen aus Objekten, Dimensionen und Messwerten zu finden und diese visuell aufzubereiten. In diesem Schritt wird aus ‚Big‘ echte ‚Smart Data‘. Das Ziel ist es Daten-Sets zu erzeugen, die ideal auf den Anwenderkontext zugeschnitten sind. Den Geschäftsführer einer globalen Modekette interessiert der Durchsatz einer Lagerzone nicht sonderlich, den Werksleiter hingegen schon. Beiden Anspruchshaltern stehen über das Datenmodell, zumindest in der Theorie, beide Ansichten zur Verfügung, da die Informationen nicht erzeugt, sondern lediglich gefiltert werden.
Wer von deskriptiver Analyse in der Intralogistik profitiert
Die einfache Antwort ist: „Alle, die ihre Geschäftsprozesse optimieren möchten.“ Wie bei allen Datenauswertungen sollten jedoch statistische Grundlagen berücksichtigt werden. Nach zehn Ereignissen lassen sich unter Umständen zwar Muster erkennen, doch ähnlich wie bei einer Umfrage unter nur zehn Personen, ist das Ergebnis nicht gesichert. Je mehr Daten und je kürzer die Zeiträume desto schneller lässt sich erkennen, wo Optimierungspotential liegt und was – noch – außerhalb der eigenen Kontrolle liegt, beispielsweise eine verminderte Leistung auf Grund von Regen. Dieses Szenario greifen wir in den folgenden Beiträgen zu ‚Diagnostic Analytics‘, ‚Predictive Analyitcs‘ und ‚Prescriptive Analytics‘ auf.
Quelle Teaser-Bild: M. B. M.
Zur Beitragsübersicht
Zu unserer TUP-Reihe KI
Zurück zur Startseite