Big Data und Smart Data sind nicht erst seit Industrie 4.0 beziehungsweise Internet of Things wichtige Bausteine eines Warehouse-Management-Systems, kurz WMS. Wie aber umgehen mit Rechner-intensiven Verfahren und komplexen Datensätzen; inmitten einer sich immer schneller bewegenden Intralogistik? Es geht um nichts Geringeres als den technologischen Fortschritt in der Lagerverwaltung: um ein noch effizienteres Handling immer größerer Auftragsmengen, um die Optimierung der Warenströme innerhalb von Lager- beziehungsweise Distributionszentren. Sprich, um den Lean-Gedanken in der Logistik.
Intelligentes Datenmanagement ist auch in der Intralogistik ein wichtiges Hilfsmittel, um einen optimalen Materialfluss zu gewährleisten. Was vor einigen Jahren noch ein Leichtes war, entwickelt sich heutzutage für einige Unternehmen zum schwer umsetzbaren Unterfangen. Warum? Die Zeit, in der Kunden zum Katalog oder zum Telefon greifen, sind schlichtweg vorbei. Nicht nur das Kaufverhalten hat sich verändert, auch das Medium. Über das Internet werden mittlerweile individuelle Produkte nachgefragt, Unternehmen müssen zunehmend diversifiziertere Programme fahren; hinzu kommen immer flexiblere und personalisierte Lieferbedingungen. Ein großes Problem sind zudem die Retouren. So gehören Mehrfachbestellungen im E-Commerce zum Standard. Kunden bestellen oftmals, weil sie ihre Größen nicht kennen, einen Artikel dreimal; gerne auch mehrfach in unterschiedlichen Farben. Die daraus resultierenden Retouren führen zu einer zusätzlichen Transport- und Lagernotwendigkeit. Spontane Kundenbestellungen sowie Same-Day-Delivery runden die aktuellen Anforderungen eines Anbieters ab. Genaue und vor allem spezifische Prognosen hinsichtlich der Prozessabläufe innerhalb eines Lagers werden immer schwieriger – so sprechen wir alleine in Deutschland von 3,4 Milliarden Paketsendungen, die etwa 2017 aus den Distributionszentren an die Kunden gingen. Aber genügt es für Vorhersagen, eine einfache Zufallsstichprobe zu nehmen? Wird ein Vorhersagemodell akkurater, wenn es über fünf Millionen Zeilen anstatt über zehn Milliarden aufzeigt? Statistisch gesehen ist der Unterschied tatsächlich zu vernachlässigen.
Wie also mit großen Datenmengen umgehen, wie schafft man einen Mehrwert? Das reine Jagen und Sammeln im Irrglauben des ‚viel hilft viel‘ ist trotz technischem Aufwand grundsätzlich einfach. Ein bewusster Paradigmenwechsel definiert allerdings ‚größer nicht immer als besser‘. Große Datenmengen sind nicht die Lösung, aber es gibt auch kein einfaches Rezept, um aus Big Data saubere und vor allem strukturierte Smart Data zu kreieren. Die Software-Manufaktur TUP (TUP) aus Stutensee versucht daher ihre logistischen Erfahrungswerte aus über 35 Jahren Intralogistik in eine Rezeptur zu gießen, um genau diese strukturierten Daten dem Kunden zur Verfügung zu stellen.
Die semantische Analyse von logistischen Prozessen ist ein besonderes Verfahren der Informationsgewinnung, welche grundsätzlich die inhaltliche Interpretation von Kennzahlen erlaubt und dank der Einbeziehung von Domänenwissen (Synonyme, Ähnlichkeiten, Ontologien sowie Taxonomien) exakte Ergebnisse liefert.
Eduard Wagner, Data-Warehouse-Spezialist und CIO TUP

Um das Potenzial von nachvollziehbaren Daten, kurz Smart Data, auszuschöpfen, setzt TUP auf fundiertes Methodenwissen, geeignete Tools sowie auf System-Activitys; sogenannte ‚Events‘. Letztere können an beliebiger Stelle zu jeder Zeit im Warehouse-Management-System platziert werden und erzeugen Messdaten dort, wo sie auch tatsächlich entstehen. Das Software-Unternehmen generiert damit direkt am Prozess selbst wertvolles Wissen und muss nicht erst aus dem Big-Data-Pool nach Informationen suchen und die unstrukturierten Daten mit hohem Aufwand zuordnen. „Der Kunde bestimmt, zu welchen Lagerprozessen Informationen benötigt werden; wir platzieren für ihn dann den entsprechenden Event. Die jeweiligen Messdaten werden von einem softwarebasierten Agenten ausgewertet und an eine sogenannte Metric-Datenbank im gewünschten Format weitergeleitet. Das Besondere: Die granularen Events werden in speziellen Time-Series-Datenbanken gespeichert; beispielsweise jeder Pick-Vorgang im WMS“, erklärt Eduard Wagner, CIO bei TUP und Data-Warehouse-Spezialist. „Klar, da kommen natürlich Massen an Daten zusammen. Doch taggen wir die jeweiligen Events im Vorfeld mit Dimensionen, die wir später nach Standort, Mandant, Zone, User sinnvoll auswerten können.“
Der Schlüssel liegt in der Konzentration auf die Qualität der Daten und die Fokussierung auf deren Kontext. So entstehen kleine intelligent zusammengestellte Datensets. „Die Perspektive des Kunden ändert sich, Daten werden im geeigneten Kontext mit Blick auf gesuchte Lösungen interpretiert – und nicht mehr nur nach zufälligen Mustern. In den Unternehmen geht es letztendlich darum die Kultur des intelligenten Datenmanagements weiterzuentwickeln hin zu einer lernenden Organisation“, ergänzt Data-Warehouse-Spezialist Wagner.
Semantische Datenanalyse mit strukturierten Daten
Wagner zielt dabei auf eine Zukunft, in der strukturierte Daten innerhalb einer semantisch geprägten Infrastruktur im Verbund genutzt werden und so den Anwender davon befreien, wissen zu müssen, wo er relevante Ergebnisse findet. Gleich dem Motto, dass erst durch eine kontinuierliche Indizierung von komplexen Logistik-Systemen und deren gespeicherten Prozess-Informationen, ein Distributionszentrum eine hohe Durchdringung von nachvollziehbaren Kennzahlen erreicht. „Wir müssen lernen, aus den Daten ein wertvolles Wirtschaftsgut zu produzieren; dem Kunden also die daraus resultierenden Erkenntnisse als gewinnbringende Resultate aufbereitet präsentieren“, so Wagner. „Nur wenn wir aus der Vergangenheit die richtigen Schlüsse ziehen, können intralogistische Prozesse in Zukunft optimiert werden. Wir versetzen so den Kunden in die profitable Lage, nachzuvollziehen, wer, was, wann, wo und wie gemacht hat – ich bin mir sogar sicher, wir wissen dann auch das Warum“, riskiert Wagner einen Blick in die Glaskugel. „Das Metric-Datenmanagement von TUP agiert als sogenannter Sourcer und interpretiert nicht nur das Verhalten einzelner Objekte innerhalb eines Intralogistik-Prozesses. Speziell die Beziehungen der Objekte zueinander spielen bei unserer Analyse eine wesentliche Rolle“, betont Wagner. „Mithilfe der Semantik können Objekte nicht nur maschinenverstehbar in Beziehung gebracht werden; Mitarbeiter und das führende Management können endlich in Echtzeit von einem Pick zum Auftrag oder zum ursprünglichen Avis im Wareneingang navigieren, um so relevante Rückschlüsse zu erhalten.“
Smart Data, Kognitive Logistik und die Sache mit den Graphen
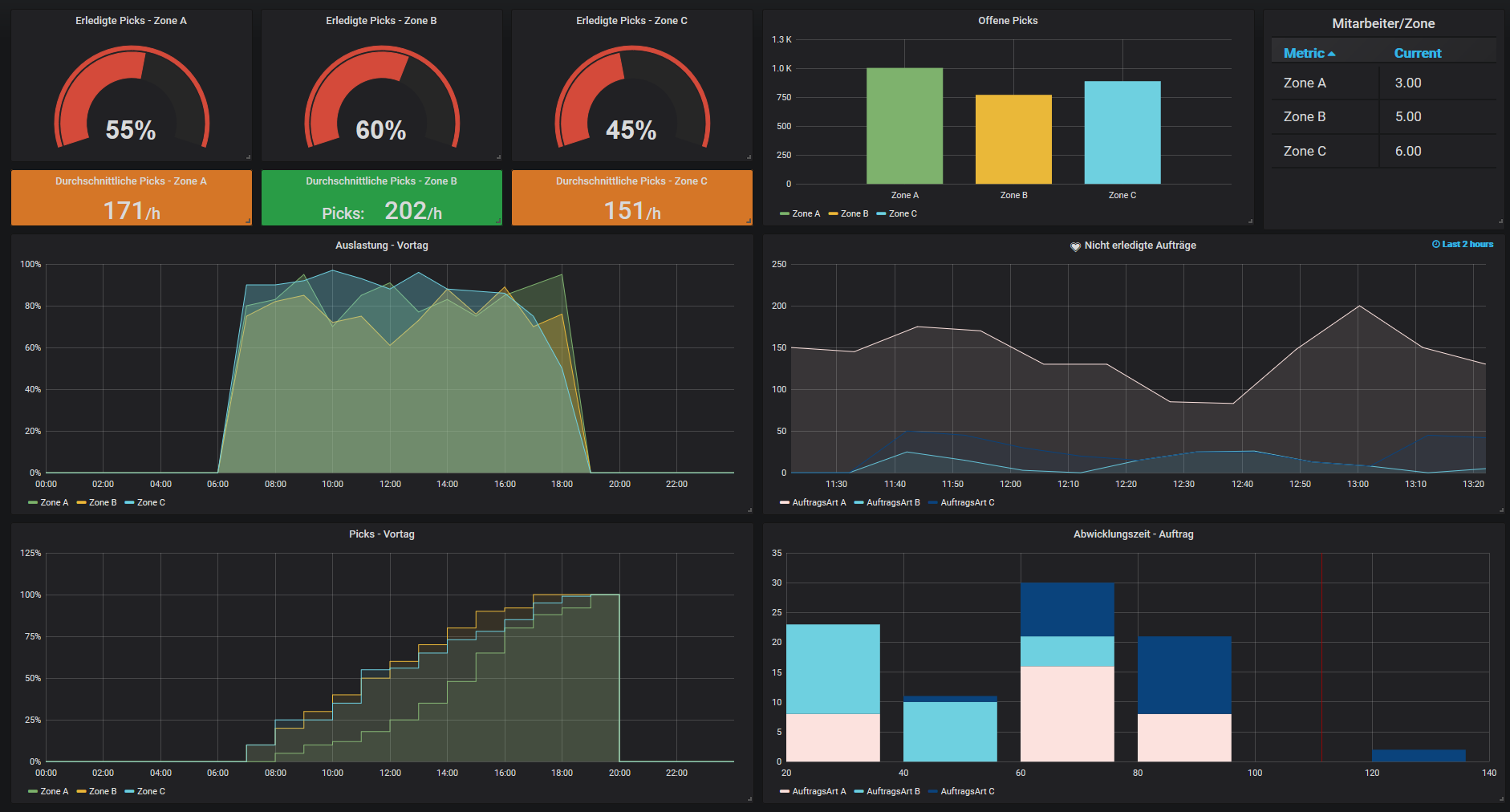 Um diese Art der kognitiven Logistik beispielsweise der Unternehmensführung auf dem Smartphone als Smart Mobile Information zu präsentieren, nutzt TUP die sogenannte Graphen-Technologie. Die Graph-Datenbanken ermöglichen es, Informationen vernetzt zu speichern, Metriken abzufragen, zu visualisieren und zu verstehen. „So können wir problemlos auf isolierte Datensilos innerhalb eines Warehouse-Management-Systems zugreifen und zeitgleich Informationen aus Wareneingang, Kommissionierung und Warenausgang sinnvoll und effektiv zusammenführen und nutzen“, erklärt Eduard Wagner. „Das Unternehmen erhält so die Fähigkeit, eigene Dashboards zusammenzustellen, Kennzahlen gegenüberzustellen und Ressourcen explizit zu analysieren. Die Analyseergebnisse können dabei in unterschiedlichen Darstellungsformen von zeitorientierten Informationen präsentiert werden (Pie, Chart, Table, Center, Alert). Da wir kundenspezifisch immer eine konkrete Aufgabenstellung erarbeiten, benötigen wir dafür kein ‚Oversizing‘ an Daten – wir taggen unsere Daten, wie bereits erwähnt, semantisch; das heißt zu Themen, die der Kunde kennt und versteht.
Um diese Art der kognitiven Logistik beispielsweise der Unternehmensführung auf dem Smartphone als Smart Mobile Information zu präsentieren, nutzt TUP die sogenannte Graphen-Technologie. Die Graph-Datenbanken ermöglichen es, Informationen vernetzt zu speichern, Metriken abzufragen, zu visualisieren und zu verstehen. „So können wir problemlos auf isolierte Datensilos innerhalb eines Warehouse-Management-Systems zugreifen und zeitgleich Informationen aus Wareneingang, Kommissionierung und Warenausgang sinnvoll und effektiv zusammenführen und nutzen“, erklärt Eduard Wagner. „Das Unternehmen erhält so die Fähigkeit, eigene Dashboards zusammenzustellen, Kennzahlen gegenüberzustellen und Ressourcen explizit zu analysieren. Die Analyseergebnisse können dabei in unterschiedlichen Darstellungsformen von zeitorientierten Informationen präsentiert werden (Pie, Chart, Table, Center, Alert). Da wir kundenspezifisch immer eine konkrete Aufgabenstellung erarbeiten, benötigen wir dafür kein ‚Oversizing‘ an Daten – wir taggen unsere Daten, wie bereits erwähnt, semantisch; das heißt zu Themen, die der Kunde kennt und versteht.
Die Software-Manufaktur aus Stutensee, bei Karlsruhe, will in Zukunft jedem Kunden ein solches Basis-Set, inklusive Dashboard und den wichtigsten Logistik-Kennzahlen, mit an die Hand geben. „Erst die Verwendung von Graphen wird uns zeigen, wo der Informationshunger individuell vertieft werden sollte. Der Kunde kann so selbst entscheiden, zu welchen Prozessen eine detailliertere Informationsdichte benötigt wird und diesen Verbund an Daten separat anfordern.“
Teaserbild: Carlos Castilla – Fotolia.com